|
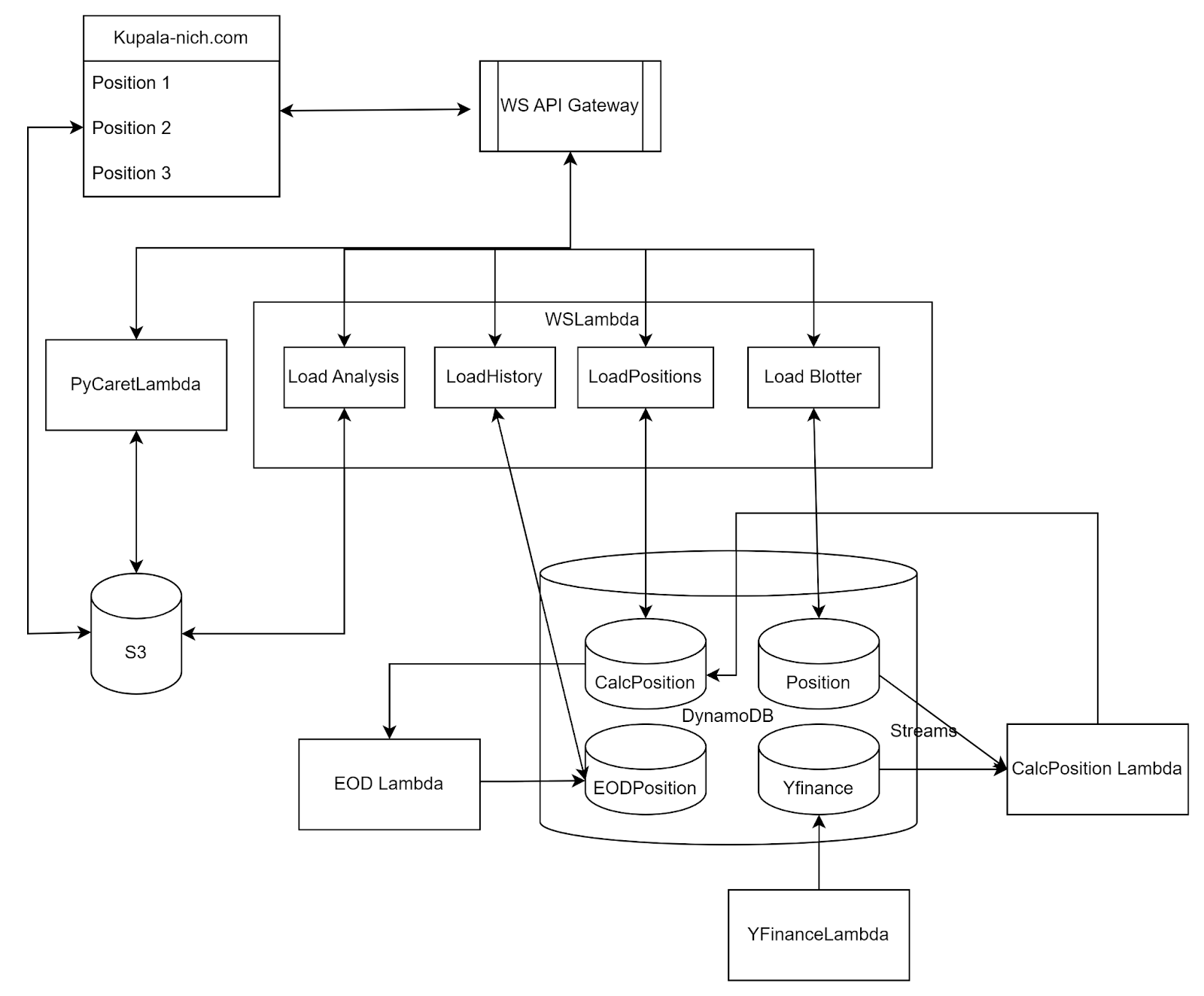
Establishing a secure foundation for the Kupala-Nich(https://kupala-nich.com) application is a critical step in transforming it from a demo to a multi-tenant application. This article outlines the security measures in place, focusing on access control, data protection, and API Gateway security. Feedback and critique are welcome to ensure these measures remain effective and resilient against emerging threats. Maintaining the integrity and confidentiality of the system is my top priority. 1. Application Access SecuritySecuring access to the Kupala-Nich application is the first line of defense. The following practices ensure robust access control:
Dynamic PoliciesLambda permissions are defined via CloudFormation templates, which are managed in code. Regular policy reviews are planned to maintain alignment with best practices and prevent privilege escalation. 2. Securing Data in AWSThe Kupala-Nich application stores all sensitive data in DynamoDB, leveraging its robust security features. DynamoDB ensures that Data at Rest and in Transit is encrypted automatically, meeting strict encryption compliance and regulatory requirements. Position and Transaction DataAfter evaluating addition additional encryption layers for position and transaction data I decided against it for the following reasons:
PII and Other Highly Sensitive DataWhile encryption secures the data within AWS, it does not protect against misuse of compromised accounts or roles. For highly sensitive data, such as personally identifiable information (PII) or vendor credentials, an additional encryption layer will be implemented Controlled Data AccessAccess to data is only available through API Gateways with built-in authentication and authorization, ensuring users can retrieve only the data they are authorized to access. More details on this are covered in the next section. Private EnvironmentsFor users requiring additional security guarantees, private environments can be created. This builds on the existing separation of production and development environments to enhance data isolation. 3. Securing API Gateway Access( Under Construction )Both WebSocket (WS) and HTTP API Gateways manage user interactions with the Kupala-Nich application. Several layers of security will ensure the protection of data: Authentication with Cognito
Authorization based on data ownership
Additional enhancementsAPI Gateway will not initially require API keys. However, API keys may be introduced in the future to enable throttling and rate-limiting of API calls, adding an extra layer of security on top of JWT-based authorization. Combining Security MeasuresKupala-Nich employs a combination of application access security, data security, and API security to provide a comprehensive approach to safeguarding the application and its data. Feedback and critique are encouraged to ensure these measures remain effective and resilient against emerging threats. As the implementation of API Gateway security is further developed, this document will be updated with additional details and implementation specifics. |